Troubleshooting
A living document of issues that we have encountered while using K-Sim
Tutorial
Troubleshooting
"Cannot initialize a EGL device display"
This error message shows up on some systems. Some users have reported fixing this by doing:
conda install -c conda-forge libstdcxx-ngHeadless Systems
When you try to render a trajectory while on a headless system, you may get an error like the following:
mujoco.FatalError: an OpenGL platform library has not been loaded into this process, this most likely means that a valid OpenGL context has not been created before mjr_makeContext was calledThe fix is to create a virtual display. If you're using Ubuntu, first install xvfb with:
sudo apt install xvfbThen run:
Xvfb :100 -ac &
PID1=$!
export DISPLAY=:100.0Alternatively (and to save yourself the pain of having to do this many times), make a systemctl service. First
sudo vim /etc/systemd/system/xvfb.serviceThen:
[Unit]
Description=Virtual Framebuffer X Server (Xvfb)
After=network.target
[Service]
ExecStart=/usr/bin/Xvfb :100 -screen 0 1024x768x24 -ac
Restart=always
Environment=DISPLAY=:100
[Install]
WantedBy=multi-user.targetFinally:
sudo systemctl enable xvfb.service
sudo systemctl start xvfb.serviceYou may also need to tell MuJoCo to use GPU accelerated off-screen rendering via
export MUJOCO_GL="egl"NaNs when running example policy
This manifests sometimes when you have an error like this:
Registers are spilled to local memory in function
We have observed this happening when training on RTX 4090s. To mitigate, disable Triton GEMM kernels:
export XLA_FLAGS='--xla_gpu_enable_latency_hiding_scheduler=true --xla_gpu_enable_triton_gemm=false'Then, you may need to remove your JAX cache to trigger JAX to rebuild the kernels:
rm -r ~/.cache/jax/jaxcacheWe've found that removing the cache can fix a number of otherwise-mysterious errors.
NaNs during training
Seeing NaNs when training a new policy is always frustrating. We have implemented a few tools in ksim to help debug such NaNs. Here is our suggested workflow:
- Make sure you are regularly saving checkpoints.
- When you start seeing NaNs, kill your training job.
- Re-run the training job initializing from the same checkpoint
JAX_DEBUG_NANS=True DISABLE_JIT_LEVEL=10 python -m examples.walking exp_dir=/path/to/exp/dir/run_NThis will disable JIT'ting the training pass of your neural network while keeping the MJX environment step JIT'ted, while also throwing an error the first time that JAX encounters a NaN.
Sudden performance drop
Sometimes you will see a sudden drop in performance, maybe after 30 minutes or an hour of training. In Tensorboard, this could look like this:
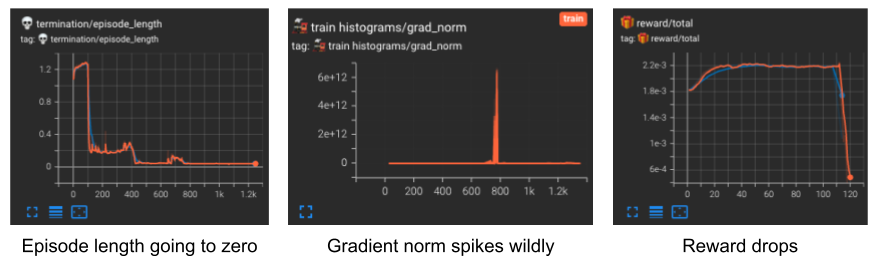
These errors are quite frustrating to debug. Fortunately, we provide some useful utility functions to help debug the root cause. Here is the suggested workflow:
- Use
DISABLE_JIT_LEVEL=21to disable JIT'ing of everything up to the core PPO algorithm, orDISABLE_JIT_LEVEL=31to disable JIT'ing the loop unrolling steps, letting you place breakpoints in the code and inspect tensors directly - Load the last checkpoint from your model using
exp_dir=/path/to/exp/dir - Lower the number of environments and batch size using
num_envs=16 batch_size=8or some similarly low values - Place a breakpoint around where you call your actor and critic, to check that the model outputs are reasonable
- Place a breakpoint after retrieving your observations, to check that the observation values are scaled properly and not blowing up
General Training Issues
If you're experiencing issues with training recurrent models, it's important to double check exactly how the carry term progresses through training. Specifically, check that the carry term in sample_action gets produced in a similar way when getting off-policy training variables.
Updated 3 months ago